2020年度新入社員研修 ー 文系出身 従来型ITからAIまで奮戦記
所属:総務部人事課
人文社会科学部 人文社会科学科/Y.C
2020年4月入社

当社にご入社される方の参考になればと思い、限られた紙面の中ですが、私が当社の研修で学んできた概要を書いてみました。
■4月~5月 研修と実践
1.研修の内容
| 社会人マナー研修 | 電話対応、メールマナー、名刺交換のマナー など |
| PG/SE基礎研修 | プロジェクトの流れ、システムについて、仮想環境構築 など |
| ウェブサイト構築研修 | HTML、CSS、JavaScriptを実際に書く など |
2.HTML、CSS、JavaScriptを使ってお客様のホームページを作成
3.私の感想
自分にとって未知の分野であったため、新しく聞く言葉も多く、入り込みにくさから難しいと感じる部分もありましが、基礎からしっかりと指導していただきました。
ホームページを作成する際、HTMLやCSSに最初のうちは慣れずに煩わしさを感じることもありました。慣れれば色々と試してみたくなり、イメージ通りに仕上がれば達成感がありました。
私の配属先は人事課でした。
人事課では人事から契約書の作成までいろいろな仕事がありますが、これら庶務の仕事と並行して、AIに関する研修も受けました。
特に人事に関して当社の業務を知る必要があるため、実践を兼ねて自然言語処理にも取り組みました。
■6月から8月 研修と実践
AI テキストマイニング(形態素解析・構文解析)

1.取り組み
(1)Python3の研修について
主として、書籍を通して学習しました。Pythonの特徴として、プログラムの読みやすさがあげられ、一番はじめに学ぶのに最もよい言語とも云われています。
(2)開発環境構築について
Anacondaを利用
Anaconda:科学計算のためのPython及びR言語の無料のオープンソースディストリビューション(色々な便利ツールをひとまとめにしたもの)です。
Anacondaには、Python本体だけでなく機械学習や科学計算でよく使うライブラリがまとめられています。
(3)ライブラリについて
使い方と適用一例
| NumPy | 配列やベクトルなど、数値計算を行う為のライブラリ |
| SciPy | 科学計算の為のライブラリ |
| Matplotlib | グラフを描画する際に使うライブラリ |
| Pandas | データ解析の為のライブラリ |
| scikit-learn | 機械学習用のライブラリ |
(4)データの処理について
データ分析・AIは課題に応じてデータ収集、データ前処理、、モデルの構築、入力・分析、検証、学習という工程をたどります。これは、テキストマイニングもデータマイニングと同じです。
(5)実際の開発について
国語の自動採点を目標とし、自然言語処理に挑戦しました。
プログラミング言語に対して、人間が扱う言語を自然言語といいます。その自然言語を機械で処理することを自然言語処理といいます。
自然言語処理は、形態素解析→構文解析→意味解析→文脈解析の流れがあります。
形態素解析とは、文法や単語の品詞情報をもとに、文章を形態素(意味を持つ最小単位)に分けることです。単に単語を切り出すだけではなく、その語の品詞や活用・語尾変化、語幹、終止形などの情報を得ることができます。
また、英語のように、言葉の区切りに空白を入れる書き方を分かち書きといいます。
日本語形態素解析ツールMeCabを用いています。
Windows版に含まれている、コンパイル済みのIPA辞書を使用しました。
得られる品詞情報は以下の通りです。
品詞, 品詞細分類1, 品詞細分類2, 品詞細分類3, 活用型, 活用形, 原形, 読み, 発音
例:日本 名詞,固有名詞,地域,国,*,*,日本,ニッポン,ニッポン

構文解析は、主語と述語の関係や目的語と述語の関係などの文法的な構造を分析します。係り受け解析とも呼ばれ、単語間の関係性についての解析を行います。
使用したツールは、日本語係り受け解析器CaboChaです。
意味解析以降は、高次な分野であり非常に難しい問題を含んでいます。単語の意味は一意には決まらないところがあります。複数の意味から、他の単語間のつながりなどを考慮して適切な一つを選ぶ必要があるなど難しいところが多くあります。
多くの文章(生徒別の解答)が与えられたとき、文章をいくつかのカテゴリに分類し、さらに、文章の中にある単語に分解して単語の出現頻度のみに着目して、文章をいくつかのカテゴリに分類する方法に潜在意味解析( Latent Semantic Analysis:LSA)があります。
最初、クラスタリングや主成分分析を使いましたが上手くいきませんでした。
潜在意味解析の問題点を解決する方法として、トピックモデルが注目を集めています。
潜在意味解析(LSA)に実装されている gensim を使いました。
gensimはトピック分析を可能にするPython3に実装されているライブラリです。
トピックとは文章の中にある主題で、文によって陳述される中心的対象をいいます。
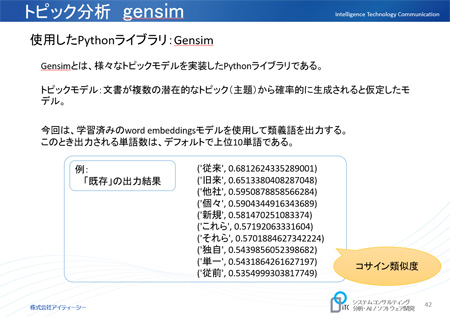
分析結果は完璧ではありませんが、各々の生徒が提出した解答に対しておおよその評価点がつけられており成果を上げられました。
2.私の感想
私は文系学部の出身で人事課の配属でしたが、人事は庶務と同時に人に関わるお仕事をするため、当社の業務内容、特に開発についてより詳しく知る必要があったため、人事のお仕事と並行して、AIの研修に入りました。自分がプログラミングを学ぶことになったときは不安を覚えました。しかしながら数ヶ月間携わってみると、拙いながらも、何とか自分でもプログラムを書くことができるようになりました。
今後は学んだことをしっかりと自分のものにしていきたいと思っています。